

I modelli linguistici di grandi dimensioni (LLM) rappresentano uno degli sviluppi più importanti nell’elaborazione del linguaggio naturale (NLP), che hanno stabilito nuovi standard su ciò che le macchine possono ottenere nella comprensione e nella generazione del linguaggio umano. Una delle sfide fondamentali della PNL è la richiesta computazionale di decodificare LLM autoregressivi. Questo processo, essenziale per attività come la traduzione automatica e il riepilogo dei contenuti, richiede notevoli risorse computazionali, rendendolo meno fattibile per applicazioni in tempo reale o su dispositivi con capacità di elaborazione limitate.

Le metodologie esistenti per affrontare la densità computazionale degli LLM includono diverse tecniche di compressione del modello come l'eliminazione della quantizzazione e le strategie di decodifica parallela. La distillazione della conoscenza è un altro approccio in cui un modello più piccolo impara dall’output di modelli più grandi. La decodifica parallela mira a generare più codici contemporaneamente, ma solleva sfide come l'output incoerente e la stima della lunghezza della risposta. I metodi condizionali vengono utilizzati nell'apprendimento multimodale, dove i modelli linguistici sono condizionati da caratteristiche visive o codificatori più grandi. Tuttavia, questi metodi spesso influiscono sulle prestazioni del modello o non riescono a ridurre in modo significativo i costi computazionali associati alla decodifica autoregressiva.

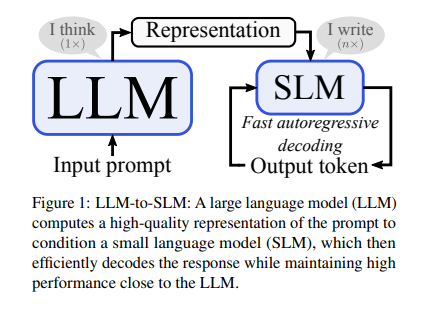
I ricercatori dell’Università di Potsdam, Qualcomm AI Research e Amsterdam hanno presentato un nuovo approccio ibrido, combinando LLM e SLM per migliorare l’efficienza della decodifica autoregressiva. Questo metodo utilizza un LLM pre-addestrato per codificare le richieste di input in parallelo e quindi condiziona l'SLM per generare la risposta successiva. Una significativa riduzione del tempo di decodifica senza sacrificare significativamente le prestazioni è un vantaggio importante di questa tecnologia.
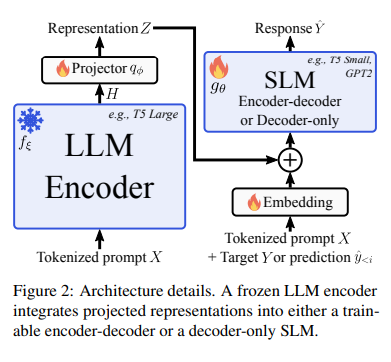
L'innovativo metodo LLM-to-SLM migliora l'efficienza degli SLM sfruttando le rappresentazioni veloci e dettagliate codificate dagli LLM. Questo processo inizia con la codifica LLM del vettore in una rappresentazione globale. Il proiettore adatta quindi questa rappresentazione allo spazio di incorporamento dell'SLM, consentendo all'SLM di generare risposte in modo regressivo. Per garantire un'integrazione fluida, il metodo sostituisce o aggiunge rappresentazioni LLM agli incorporamenti SLM, dando priorità all'adattamento in fase iniziale per mantenere la semplicità. Allinea le lunghezze delle sequenze utilizzando il codice LLM, garantendo che SLM possa interpretare il vettore in modo accurato, sposando così la profondità degli LLM con la flessibilità degli SLM per una decodifica efficiente.

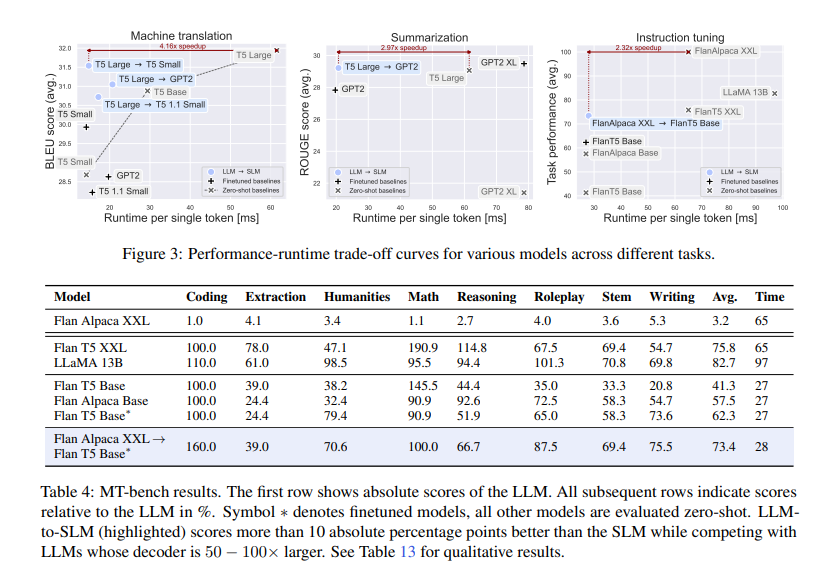
L'approccio ibrido proposto ha ottenuto notevoli accelerazioni fino a 4×, con piccole penalità prestazionali dell'1-2% per le attività di traduzione e riepilogo rispetto a LLM. L'approccio LLM-to-SLM ha eguagliato le prestazioni di LLM pur essendo 1,5 volte più veloce, rispetto all'accelerazione di 2,3 volte del solo LLM-to-SLM. La ricerca ha inoltre riportato risultati aggiuntivi per l'attività di traduzione, dimostrando che l'approccio LLM-to-SLM può essere utile per periodi di generazione brevi e che il suo numero di FLOP è simile a quello di SLM.
In conclusione, l'articolo fornisce una soluzione convincente alle sfide computazionali della decodifica autoregressiva in modelli linguistici di grandi dimensioni. Combinando brillantemente le capacità di codifica complete degli LLM con la velocità degli SLM, il team ha aperto nuove strade per le applicazioni di elaborazione del linguaggio in tempo reale. Questo approccio ibrido mantiene elevati livelli di prestazioni e riduce significativamente i requisiti computazionali, mostrando una direzione promettente per i progressi futuri in questo campo.
Controlla il carta. Tutto il merito di questa ricerca va ai ricercatori di questo progetto. Inoltre non dimenticare di seguirci Twitter E Google News. si unisce Abbiamo oltre 38.000 subReddit ML, Oltre 41.000 comunità Facebook, Canale DiscordiaE Grammo di LinkedInoperazione.
Se ti piace il nostro lavoro, adorerai il nostro lavoro le notizie..
Non dimenticare di unirti a noi Canale Telegram
Potrebbe piacerti anche il nostro Corsi gratuiti di intelligenza artificiale….


Nikhil è un consulente tirocinante presso Marktechpost. Sta conseguendo una doppia laurea integrata in materie presso l'Indian Institute of Technology, Kharagpur. Nikhil è un appassionato di intelligenza artificiale/ML ed è sempre alla ricerca di applicazioni in settori come i biomateriali e le scienze biomediche. Con un forte background nella scienza dei materiali, esplora nuovi sviluppi e crea opportunità per contribuire.

Federico Caruso è autore per Gossipitaliano.net e si occupa di seguire l’attualità con un approccio chiaro, accurato e orientato ai lettori. Scrive su temi che spaziano dalle notizie di cronaca e politica al business, dalla tecnologia allo sport, fino all’intrattenimento e al lifestyle. Il suo obiettivo è offrire informazioni affidabili, spiegazioni comprensibili e approfondimenti sui fatti e sulle storie che hanno un impatto concreto sulla vita quotidiana e sull’interesse del pubblico.